The advanced capabilities of ChatGPT, such as debugging code, writing essays, and cracking jokes, have made it incredibly popular. However, it has been limited to working with text only. That is about to change.
OpenAI recently introduced GPT-4, an impressive multimodal model that can accept both text and image inputs and provide text outputs.
Also: Learn how to make ChatGPT provide sources and citations
While the differences between GPT-3.5 and GPT-4 may be subtle in casual conversation, the new model is significantly more reliable, creative, and intelligent.
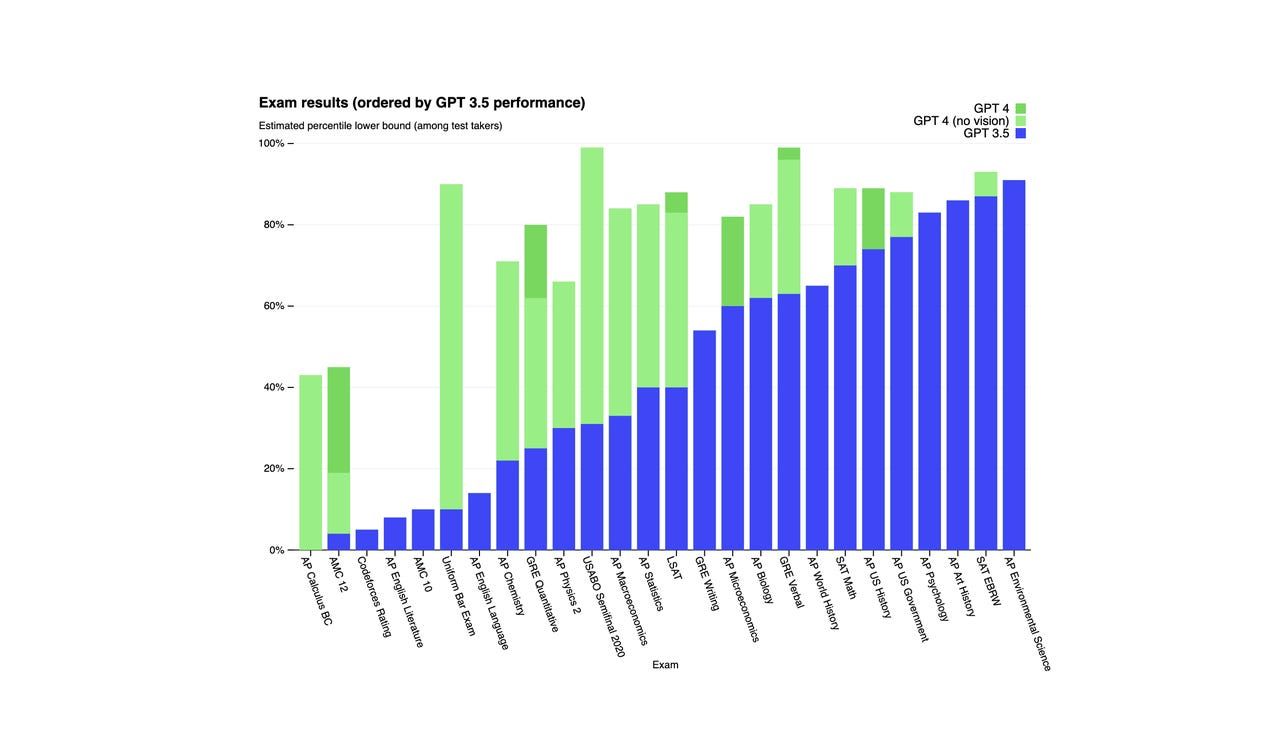
According to OpenAI, GPT-4 scored in the top 10% of a simulated bar exam, whereas GPT-3.5 scored in the bottom 10%. GPT-4 also outperformed GPT-3.5 in a variety of benchmark tests, as shown in the graph below:

For context, ChatGPT currently relies on a language model fine-tuned from a model in the 3.5 series, which limits the chatbot to delivering text outputs only.
The announcement of GPT-4 by OpenAI followed a recent statement from Andreas Braun, CTO of Microsoft Germany, in which he mentioned the upcoming release of GPT-4 and its potential for text-to-video generation.
Also: How does ChatGPT work?
"We will introduce GPT-4 next week, offering completely different possibilities with multimodal models such as videos," Braun stated according to Heise, a German news outlet.
Although GPT-4 is a multimodal model, the claims about text-to-video generation were somewhat exaggerated. It cannot yet produce videos, but it can accept visual inputs, which is still a significant advancement from the previous model.
One example provided by OpenAI demonstrates ChatGPT analyzing an image in response to a request from the user to identify what about the photo is humorous.
Other examples include uploading a graph image and asking GPT-4 to perform calculations based on it, or uploading a worksheet and requesting it to solve the questions.
Also: Discover 5 ways ChatGPT can assist you in writing an essay
OpenAI plans to release GPT-4's text input capabilities via ChatGPT and its API through a waitlist. However, the image input feature will take longer to become available, as OpenAI is currently collaborating with a single partner to get it started.
If you were hoping for a text-to-video generator, don't worry: it's not an entirely novel idea. Tech giants like Meta and Google are already working on their own models. Meta has Make-A-Video, and Google has Imagen Video, both of which utilize AI to generate videos based on user input.